I can confirm I am experiencing the same issue and I've managed to solve it, but it's a rather ugly solution - in SCM Draft you have to enter all your strings in ANSI format. How you do it:
1) open notepad++(what I use to edit text, any other text editor with encoding options should work)
2) open the menu "Encoding" and make sure that "utf-8" is highlighted. That means that text that you enter will be stored in utf-8 format.
2) enter the russian text you want to display. Note that this text will be stored in UTF-8 format and is displayed to you in utf-8 format.
3) go to the menu Encoding => UTF-8 should be highlighted .. click on ANSI. This converts the utf text into ANSI. In other words, this keeps the bits 010101 the same, but display them using different rules(different encoding scheme) - displaying each byte(8 bits, a sequence of 8 boolean values( 0-s or 1-s)) as a separate character. For example the text "тест кирилица utf"(A)(utf-cyr, has 17 characters, stored as 29 bytes) should be converted to "тест кирилица utf"(B)(ANSI-29 characters, stored as 29 bytes-garbage text) ( Note that I'm not sure whether or how these two strings will be displayed on the staredit forum, but for me they look VERY differently)
4) Now copy that text (B) and paste it into SCM Draft. I renamed a firebat to the the (B) text. In game the firebat name is displayed with proper cyrillic characters - magic!
Do this for all strings that contain cyrillic. I imagine it's gonna be a long night for you.

The reason that works:
- SCM Draft doesn't understand utf-8 => if you type utf-8 characters they get stored in the map file using your local codepage settings(russian 1251, 1 byte per character), not with utf-8 rules(2 bytes per character), but with your local encoding table settings(in other words, your System locale)(that is found in Start menu => Control panel => Language => Change date, time, or number formats => Administrative => Change system locale - look at the language, then google search "locale language" and check the list to see yours... I'm using Bulgarian, so it's codepage 1251... Russian is also 1251, so it's using the same rules and will store russian characters that you type in the same way as bulgarian characters that I type. The problem is that each character is stored as 1 byte, possibly different from the 2-byte format that UTF-8 uses. Some characters maybe the same(latin characters like "utf 8" that are the same in both utf-8 format and in the 1251 codepage), but the russian part is garbled and unreadable. In end effect you store that string using only 17 bytes, because you have a string of 17 characters, each of which is translated into 1 byte using your local codepage. This happens because SCM Draft is stupid and can't read utf-8 text.
- SCM Draft understands ANSI - if you convert your text (17 characters of utf-8) into ANSI, each "russian" character is broken down into 2 bytes(because the utf-8 representation of russian has 2 bytes per character) and since there are 12 russian characters you end up with 29 bytes:
-- 17(utr-8) characters have 12 russian and 5 non-russian characters.
-- 29 ANSI characters have 12 x 2(russian) + 5 x 1(non-russian) characters
So you store 29 characters, exactly how the bytes should be stored.
Starcraft can read utf-8 and will read those 29 bytes as utf-8. Thus, it displays the proper text. However, SCM Draft doesn't and this is a problem if you want to edit text in SCM Draft(to improve formatting), since after copying it's an unreadable mess - you can only read it in game.
I've had trouble with translating maps from korean due to the same issue - text is saved in korean, but when I open the map in scm draft it shows that text not in utf-8, but in my local language(1251, which doesn't have korean and treats characters differently) and everything is garbled(well, not everything, but all korean text is). Farty1billion helped me udnerstand the issue and gave me a quick solution -
this website he made to convert text.
I hope I've answered your question and shed light on the issue. it's tricky and annoying that SCM Draft doesn't support utf-8 while SCR does.
None.

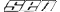





") the text will seem(more or less) to be Russian/Bulgarian, but will in fact be utf-8 latin. The problem is when there are characters that latin doesn't have... in which case you have to find a smart way to display them.
the text will seem(more or less) to be Russian/Bulgarian, but will in fact be utf-8 latin. The problem is when there are characters that latin doesn't have... in which case you have to find a smart way to display them.  Moose -- lil-Inferno
Moose -- lil-Inferno NudeRaider -- Vrael
NudeRaider -- Vrael
